Machine Learning for Result Estimation
Introduction
High level Synthesis tools are greatly used in logic synthesis. The reports from HLS tools provide important guidance for tuning the high-level directives. However, acquiring accurate result estimation in an early stage is difficult due to complex optimizations in the physical synthesis, imposing a trade-off between accuracy (waiting for post-synthesis results) and efficiency (evaluating in the HLS stage). ML can be used to improve the accuracy of HLS reports through learning from real design benchmarks.
Estimation of Timing, Resource Usage and Operation Delay:
The overall workflow of timing and resource usage prediction is as shown in the following figure.
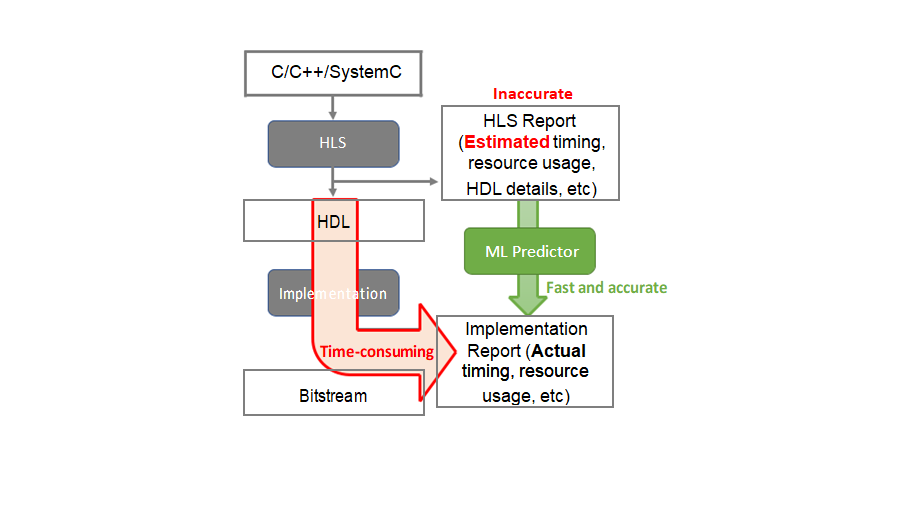
The main methodology is to train an ML model that takes HLS reports as input and outputs a more accurate implementation report without conducting the time-consuming post-implementation. The workflow can be divided into two steps: data processing and training estimation models.
Step 1 - Data Processing: To enable ML for HLS estimation, we need a dataset for training and testing. The HLS and implementation reports are usually collected across individual designs by running each design through the complete C-to-bitstream flow, for various clock periods and targeting different FPGA devices. After that, one can extract features from the HLS reports as inputs and features from implementation reports as outputs. Besides, to overcome the effect of collinearity and reduce the dimension of the data, previous studies often apply feature selection techniques to systematically remove unimportant features.
Step 2 - Training Estimation Models: After constructing the dataset, regression models are trained to estimate post-implementation resource usages and clock periods. Frequently used metrics to report the estimation error include relative absolute error (RAE) and relative root mean squared error (RMSE). For both metrics, lower is better.
ML techniques have been applied recently to reduce the HLS tool’s prediction error of the operation delay. Existing HLS tools perform delay estimations based on the simple addition of pre-characterized delays of individual operations, and can be inaccurate because of the post-implementation optimizations (e.g., mapping to hardened blocks like DSP adder cluster). A customized Graph Neural Network (GNN) model is built to capture the association between operations from the dataflow graph, and train this model to infer the mapping choices about hardened blocks.
Cross-Platform Performance Prediction
Hardware/software co-design enables designers to take advantage of new hybrid platforms such as Zynq. However, dividing an application into two parts makes the platform selection difficult for the developers, since there is a huge variation in the application’s performance of the same workload across various platforms. To avoid fully implementing the design on each platform, an ML-based cross-platform performance estimator, XPPE is used. The key functionality of XPPE is using the resource utilization of an application on one specific FPGA to estimate its performance on other FPGAs.

Comments
Post a Comment